虚拟线程最佳实践
Virtual Threads: An Adoption Guide
虚拟线程:采用指南
原文:https://docs.oracle.com/en/java/javase/21/core/virtual-threads.html
虚拟线程是由 Java 运行时而不是操作系统实现的 Java 线程。虚拟线程和传统线程(我们称之为平台线程)之间的主要区别在于,我们可以轻松地在同一个 Java 进程中运行大量活动虚拟线程,甚至数百万个。虚拟线程的数量众多,赋予了虚拟线程强大的力量:通过允许服务器同时处理更多请求,它们可以更有效地运行以每个请求线程风格编写的服务器应用程序,从而提高吞吐量并减少硬件浪费。
由于虚拟线程是 java.lang.Thread 的实现,并且遵守自 Java SE 1.0 以来指定 java.lang.Thread 的相同规则,因此开发人员无需学习新概念即可使用它们。然而,由于无法生成大量平台线程(多年来 Java 中唯一可用的线程实现),已经产生了旨在应对其高成本的实践。这些做法在应用于虚拟线程时会适得其反,必须摒弃。此外,成本上的巨大差异提供了一种新的思考线程的方式,而这些线程一开始可能是陌生的。
本指南无意全面涵盖虚拟线程的每个重要细节。其目的只是提供一套介绍性指南,以帮助那些希望开始使用虚拟线程的人充分利用它们。
Write Simple, Synchronous Code Employing Blocking I/O APIs in the Thread-Per-Request Style
使用阻塞 I/O API 以每个请求线程的方式编写简单的同步代码
虚拟线程可以显着提高以每个请求线程风格编写的服务器的吞吐量(而不是延迟)。在这种风格中,服务器专用一个线程在整个持续时间内处理每个传入请求。它至少专用一个线程,因为在处理单个请求时,您可能希望使用更多线程来同时执行某些任务。
阻塞平台线程的成本很高,因为它保留了线程(一种相对稀缺的资源),而它没有做太多有意义的工作。因为虚拟线程可能很丰富,所以阻塞它们是廉价的并且值得鼓励。因此,您应该以简单的同步风格编写代码并使用阻塞 I/O API。
例如,以下以非阻塞异步风格编写的代码不会从虚拟线程中受益太多。
1 | |
另一方面,以下以同步风格编写并使用简单阻塞 IO 的代码将受益匪浅:
1 | |
此类代码也更容易在调试器中调试、在分析器中分析或通过线程转储进行观察。要观察虚拟线程,请使用 jcmd 命令创建线程转储:
1 | |
Represent Every Concurrent Task as a Virtual Thread; Never Pool Virtual Threads
将每个并发任务表示为一个虚拟线程;从不池化虚拟线程
关于虚拟线程最难理解的事情是,虽然它们具有与平台线程相同的行为,但它们不应该代表相同的程序概念。
平台线程稀缺,因此是宝贵的资源。宝贵的资源需要管理,管理平台线程最常见的方法是使用线程池。然后您需要回答的一个问题是,池中应该有多少个线程?
但虚拟线程非常丰富,因此每个虚拟线程不应代表某些共享的、池化的资源,而应代表一个任务。线程从托管资源转变为应用程序域对象。我们应该有多少个虚拟线程的问题变得显而易见,就像我们应该使用多少个字符串在内存中存储一组用户名的问题一样显而易见:虚拟线程的数量始终等于并发任务的数量在您的应用程序中。
将 n 个平台线程转换为 n 个虚拟线程不会产生什么好处;相反,它是需要转换的任务。
要将每个应用程序任务表示为一个线程,请不要使用共享线程池执行器,如下例所示:
1 | |
相反,请使用虚拟线程执行器,如下例所示:
1 | |
该代码仍然使用 ExecutorService ,但从 Executors.newVirtualThreadPerTaskExecutor() 返回的不使用线程池。相反,它为每个提交的任务创建一个新的虚拟线程。
此外, ExecutorService 本身是轻量级的,我们可以像创建任何简单对象一样创建一个新对象。这使我们能够依赖新添加的 ExecutorService.close() 方法和 try-with-resources 构造。在 try 块末尾隐式调用的 close 方法将自动等待提交给 ExecutorService 的所有任务,即由 ExecutorService ——终止。
对于调用外部请求来说,这是一种特别有用的模式,在这种场景中,您希望同时对不同的服务执行多个传出调用,如下例所示:
1 | |
您应该为即使是小型、短期的并发任务创建一个新的虚拟线程,如上所示。
为了获得更多帮助编写此模式和其他常见并发模式,并具有更好的可观察性,请使用结构化并发。
根据经验,如果您的应用程序从未拥有 10,000 个或更多虚拟线程,则它不太可能从虚拟线程中受益。要么它的负载太轻而需要更高的吞吐量,要么您没有向虚拟线程表示足够多的任务。
Use Semaphores to Limit Concurrency
使用信号量限制并发
有时需要限制某个操作的并发数。例如,某些外部服务可能无法处理超过 10 个并发请求。由于平台线程是一种宝贵的资源,通常在池中进行管理,因此线程池已经变得如此普遍,以至于它们被用于限制并发的目的,如下例所示:
1 | |
此示例确保有限服务最多有 10 个并发请求。
但限制并发只是线程池操作的副作用。池旨在共享稀缺资源,而虚拟线程并不稀缺,因此永远不应该池化!
使用虚拟线程时,如果要限制访问某些服务的并发性,则应该使用专门为此目的设计的构造: Semaphore 类。下面的例子演示了这个类:
1 | |
碰巧调用 foo 的线程将受到限制,即被阻塞,因此一次只有 10 个线程可以取得进展,而其他线程将不受阻碍地继续其业务。
简单地使用信号量阻塞某些虚拟线程可能看起来与将任务提交到固定线程池有很大不同,但事实并非如此。将任务提交到线程池会将它们排队以供稍后执行,但内部信号量(或与此相关的任何其他阻塞同步构造)会创建一个在其上阻塞的线程队列,该队列镜像等待池线程执行的任务队列。执行他们。因为虚拟线程是任务,所以结果结构是等效的:
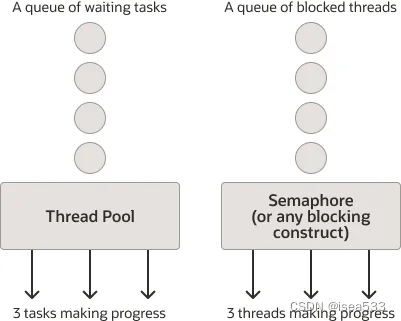
尽管您可以将平台线程池视为处理从队列中提取的任务的工作人员,并将虚拟线程视为任务本身,在它们可以继续之前被阻塞,但计算机中的底层表示实际上是相同的。认识排队任务和阻塞线程之间的等效性将帮助您充分利用虚拟线程。
数据库连接池本身充当信号量。连接池限制为十个连接将阻止第十一个线程尝试获取连接。无需在连接池之上添加额外的信号量。
Don’t Cache Expensive Reusable Objects in Thread-Local Variables
不要在线程局部变量中缓存昂贵的可重用对象
虚拟线程支持线程局部变量,就像平台线程一样。有关详细信息,请参阅线程局部变量。通常,线程局部变量用于将一些特定于上下文的信息与当前运行的代码关联起来,例如当前事务和用户ID。对于虚拟线程来说,线程局部变量的使用是完全合理的。但是,请考虑使用更安全、更有效的范围值。有关详细信息,请参阅范围值。
线程局部变量的另一种用途与虚拟线程根本上是不一致的:缓存可重用对象。这些对象的创建成本通常很高(并且消耗大量内存),并且是可变的,并且不是线程安全的。它们被缓存在线程局部变量中,以减少它们实例化的次数以及它们在内存中的实例数量,但它们可以被线程上不同时间运行的多个任务重用。
例如, SimpleDateFormat 的实例创建成本很高,而且不是线程安全的。出现的一种模式是将此类实例缓存在 ThreadLocal 中,如下例所示:
1 | |
仅当线程(以及因此在线程本地缓存的昂贵对象)被多个任务共享和重用时(就像平台线程被池化时的情况一样),这种缓存才有用。许多任务在线程池中运行时可能会调用 foo ,但由于池中仅包含几个线程,因此该对象只会实例化几次(每个池线程一次)并被缓存和重用。
但是,虚拟线程永远不会被池化,也不会被不相关的任务重用。因为每个任务都有自己的虚拟线程,所以每次从不同任务调用 foo 都会触发新的 SimpleDateFormat 的实例化。而且,由于可能有大量的虚拟线程同时运行,昂贵的对象可能会消耗相当多的内存。这些结果与线程本地缓存想要实现的结果恰恰相反。
没有提供单一的通用替代方案,但对于 SimpleDateFormat ,您应该将其替换为 DateTimeFormatter 。 DateTimeFormatter 是不可变的,因此单个实例可以由所有线程共享:
1 | |
请注意,使用线程局部变量来缓存共享的昂贵对象有时是由异步框架在幕后完成的,其隐含的假设是它们由极少数池线程使用。这就是为什么混合虚拟线程和异步框架不是一个好主意的原因之一:对方法的调用可能会导致在本来要缓存和共享的线程局部变量中实例化昂贵的对象。
Avoid Lengthy and Frequent Pinning
避免长时间和频繁的固定
当前虚拟线程实现的一个限制是,在 synchronized 块或方法内执行阻塞操作会导致 JDK 的虚拟线程调度程序阻塞宝贵的操作系统线程,而如果阻塞操作则不会阻塞在 synchronized 块或方法之外完成。我们称这种情况为“固定”。如果阻塞操作既长期又频繁,则固定可能会对服务器的吞吐量产生不利影响。保护短期操作(例如内存中操作)或使用 synchronized 块或方法的不频繁操作应该不会产生不利影响。
为了检测可能有害的固定实例,(JDK Flight Recorder (JFR) 在固定阻塞操作时发出 jdk.VirtualThreadPinned 线程;默认情况下,当操作时间超过 20 毫秒时启用此事件。
或者,您可以使用系统属性 jdk.tracePinnedThreads 在线程固定时阻塞时发出堆栈跟踪。使用选项 -Djdk.tracePinnedThreads=full 运行会在线程被固定时阻塞时打印完整的堆栈跟踪,突出显示本机帧和持有监视器的帧。使用选项 -Djdk.tracePinnedThreads=short 运行将输出限制为仅有问题的帧。
如果这些机制检测到固定既长期又频繁的位置,请在这些特定位置将 synchronized 替换为 ReentrantLock(同样,无需替换 synchronized 它保护短暂或不频繁的操作)。以下是长期且频繁使用 syncrhonized 块的示例。
1 | |
您可以将其替换为以下内容:
1 | |