Hi @abel533, how can I help you? I’m powered by AI, so surprises and mistakes are possible. Make sure to verify any generated code or suggestions, and share feedback so that we can learn and improve.
// 1. Query all data from itsm_base_enterprisemanagement Stringquery="SELECT * FROM itsm_base_enterprisemanagement"; ResultSetrs= stmt.executeQuery(query);
// 2. Get the metadata of the result set ResultSetMetaDatarsmd= rs.getMetaData(); intcolumnCount= rsmd.getColumnCount();
// 3. Create ES index StringindexName="itsm_base_enterprisemanagement_index"; CreateIndexRequestrequest=newCreateIndexRequest(indexName);
// 4. Insert all data into ES index while (rs.next()) { Map<String, Object> jsonMap = newHashMap<>(); for (inti=1; i <= columnCount; i++) { jsonMap.put(rsmd.getColumnName(i), rs.getObject(i)); }
// 1. Query all data from itsm_base_enterprisemanagement Stringquery="SELECT * FROM itsm_base_enterprisemanagement"; ResultSetrs= stmt.executeQuery(query);
// 2. Get the metadata of the result set ResultSetMetaDatarsmd= rs.getMetaData(); intcolumnCount= rsmd.getColumnCount();
// 3. Create ES index StringindexName="itsm_base_enterprisemanagement_index";
// Create index request RequestcreateIndexRequest=newRequest("PUT", "/" + indexName); createIndexRequest.setJsonEntity( "{\n" + " \"mappings\": {\n" + " \"properties\": {\n" + // Add fields to the index " }\n" + " }\n" + "}" ); ResponsecreateIndexResponse= restClient.performRequest(createIndexRequest);
// 4. Insert all data into ES index while (rs.next()) { Map<String, Object> jsonMap = newHashMap<>(); for (inti=1; i <= columnCount; i++) { jsonMap.put(rsmd.getColumnName(i), rs.getObject(i)); }
// Add fields to the index for (inti=1; i <= columnCount; i++) { mappings.append(" \"").append(rsmd.getColumnName(i)).append("\": {\n"); mappings.append(" \"type\": \"text\"\n"); mappings.append(" },\n"); }
// Remove the last comma and close the JSON object mappings.setLength(mappings.length() - 2); mappings.append("\n }\n }\n}");
// Add fields to the index for (inti=1; i <= columnCount; i++) { mappings.append(" \"").append(rsmd.getColumnName(i)).append("\": {\n"); mappings.append(" \"type\": \"").append(convertSqlTypeToESType(rsmd.getColumnType(i))).append("\"\n"); mappings.append(" },\n"); }
// Remove the last comma and close the JSON object mappings.setLength(mappings.length() - 2); mappings.append("\n }\n }\n}");
这段代码将遍历结果集的元数据,获取每个列的名称和类型,并将这些名称和类型作为 ES 索引的字段和类型。然后,它将创建一个包含这些字段和类型的 ES 索引。 请注意,我添加了一个名为 convertSqlTypeToESType 的方法,该方法将 SQL 类型转换为 ES 类型。这是该方法的一个简单实现:
privatestatic String convertSqlTypeToESType(int sqlType) { switch (sqlType) { case Types.INTEGER: case Types.TINYINT: case Types.SMALLINT: case Types.BIGINT: return"integer"; case Types.FLOAT: case Types.REAL: case Types.DOUBLE: case Types.NUMERIC: case Types.DECIMAL: return"float"; case Types.BOOLEAN: return"boolean"; case Types.DATE: case Types.TIME: case Types.TIMESTAMP: return"date"; default: return"text"; } }
这个方法根据 SQL 类型返回对应的 ES 类型。如果 SQL 类型不在这个方法处理的范围内,那么默认返回”text”。您可能需要根据实际需求修改这个方法。
ASK:
new Request("POST", "/" + indexName + "/\_doc") 这里能否改为批量插入?
GitHub Copilot:
是的,Elasticsearch REST Client 支持批量插入操作。我们可以使用”_bulk” API 来进行批量插入。以下是修改后的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// 4. Insert all data into ES index StringBuilderbulkRequestBody=newStringBuilder(); while (rs.next()) { Map<String, Object> jsonMap = newHashMap<>(); for (inti=1; i <= columnCount; i++) { jsonMap.put(rsmd.getColumnName(i), rs.getObject(i)); }
// Create index request bulkRequestBody.append("{\"index\":{\"_index\":\"").append(indexName).append("\"}}\n"); bulkRequestBody.append(jsonMap.toString()).append("\n"); }
// 4. Insert all data into ES index StringBuilderbulkRequestBody=newStringBuilder(); intcount=0; while (rs.next()) { Map<String, Object> jsonMap = newHashMap<>(); for (inti=1; i <= columnCount; i++) { jsonMap.put(rsmd.getColumnName(i), rs.getObject(i)); }
// Create index request bulkRequestBody.append("{\"index\":{\"_index\":\"").append(indexName).append("\"}}\n"); bulkRequestBody.append(jsonMap.toString()).append("\n");
count++;
// Execute bulk request every 100 records if (count % 100 == 0) { RequestbulkRequest=newRequest("POST", "/_bulk"); bulkRequest.setJsonEntity(bulkRequestBody.toString()); ResponsebulkResponse= restClient.performRequest(bulkRequest);
// Clear the bulk request body bulkRequestBody.setLength(0); } }
// Execute the remaining requests if there are less than 100 if (bulkRequestBody.length() > 0) { RequestbulkRequest=newRequest("POST", "/_bulk"); bulkRequest.setJsonEntity(bulkRequestBody.toString()); ResponsebulkResponse= restClient.performRequest(bulkRequest); }
这段代码将遍历结果集,为每一行数据创建一个索引请求,并将这些请求添加到批量请求的主体中。每当累计到 100 条数据时,它就会执行一次批量请求。如果最后还剩下少于 100 条数据,它也会执行一次批量请求,以确保所有数据都被插入到 ES 索引中。
请注意,size 参数的最大值是 10000。如果你需要处理超过 10000 条的结果,你可能需要使用 scroll API 或者 search_after 参数。
ASK:
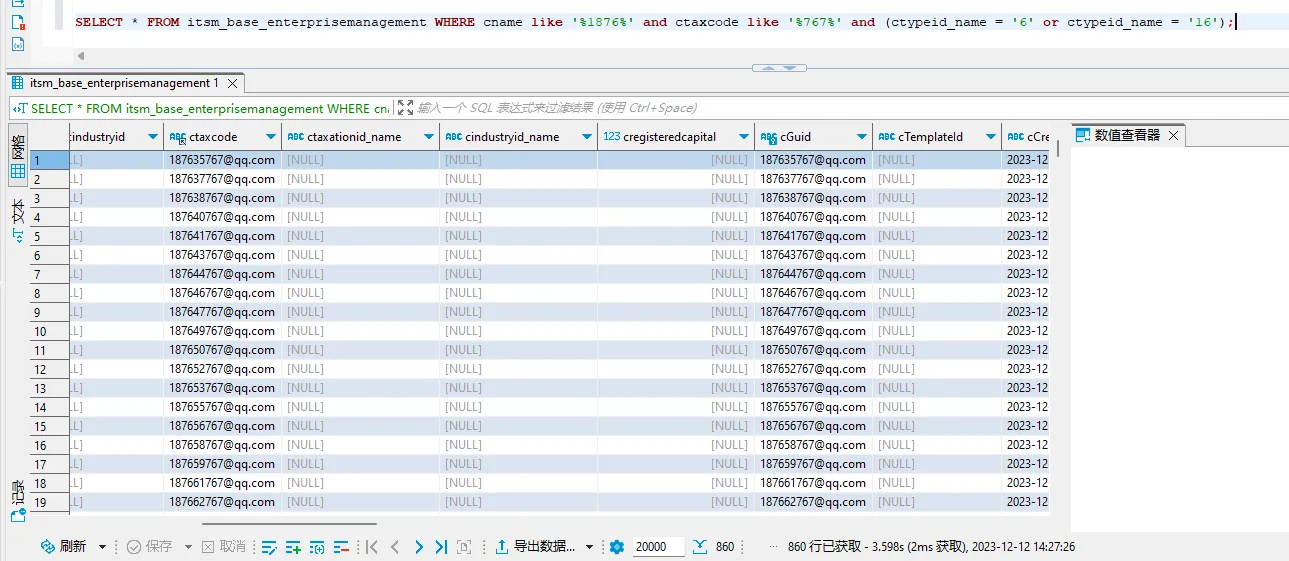
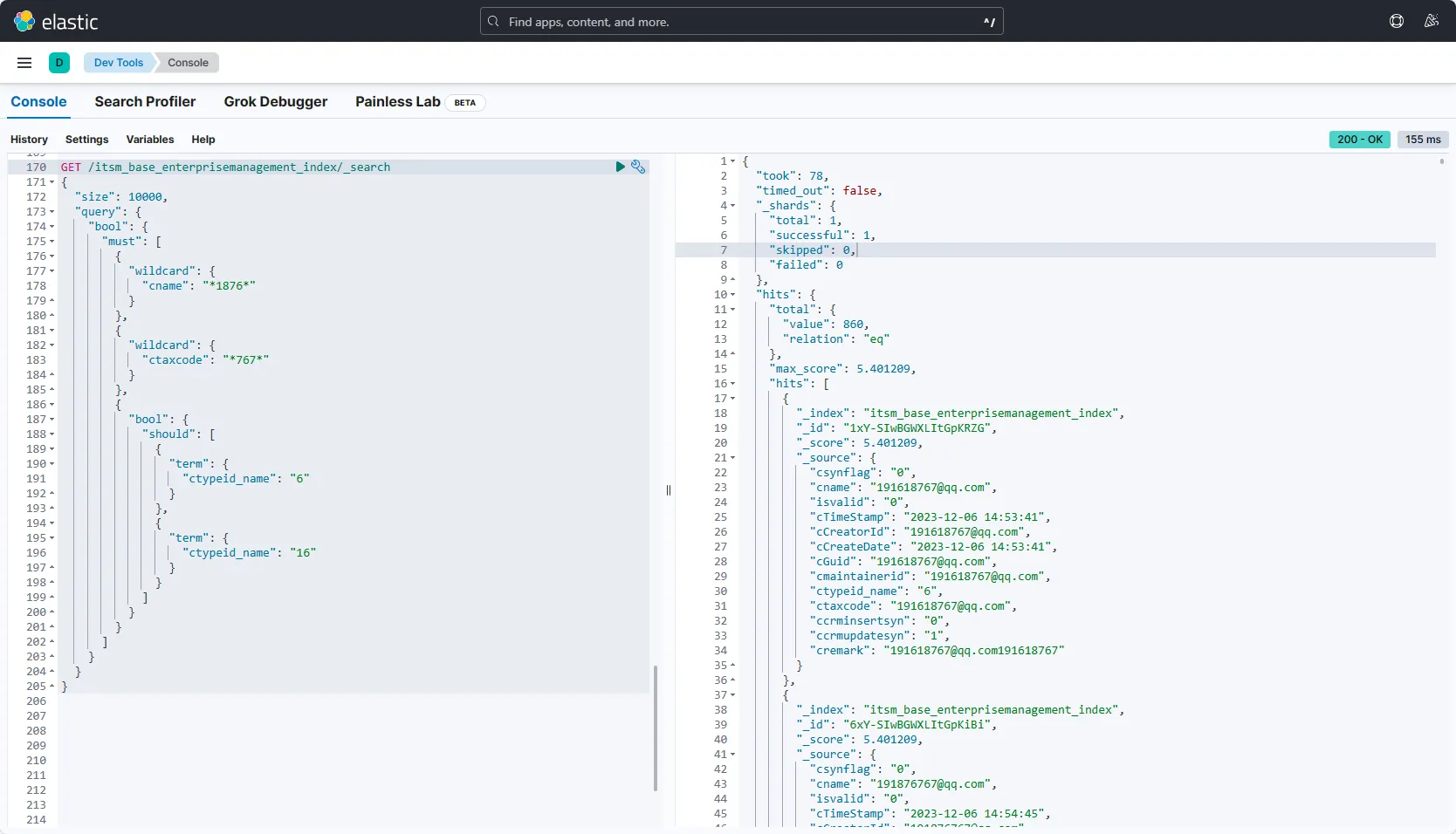
将 SQL 形式的查询转换为 kibana 中的 HTTP 形式:SELECT * FROM itsm_base_enterprisemanagement WHERE cname like '%1876%' and ctaxcode like '%767%' and (ctypeid_name = '6' or ctypeid_name = '16');